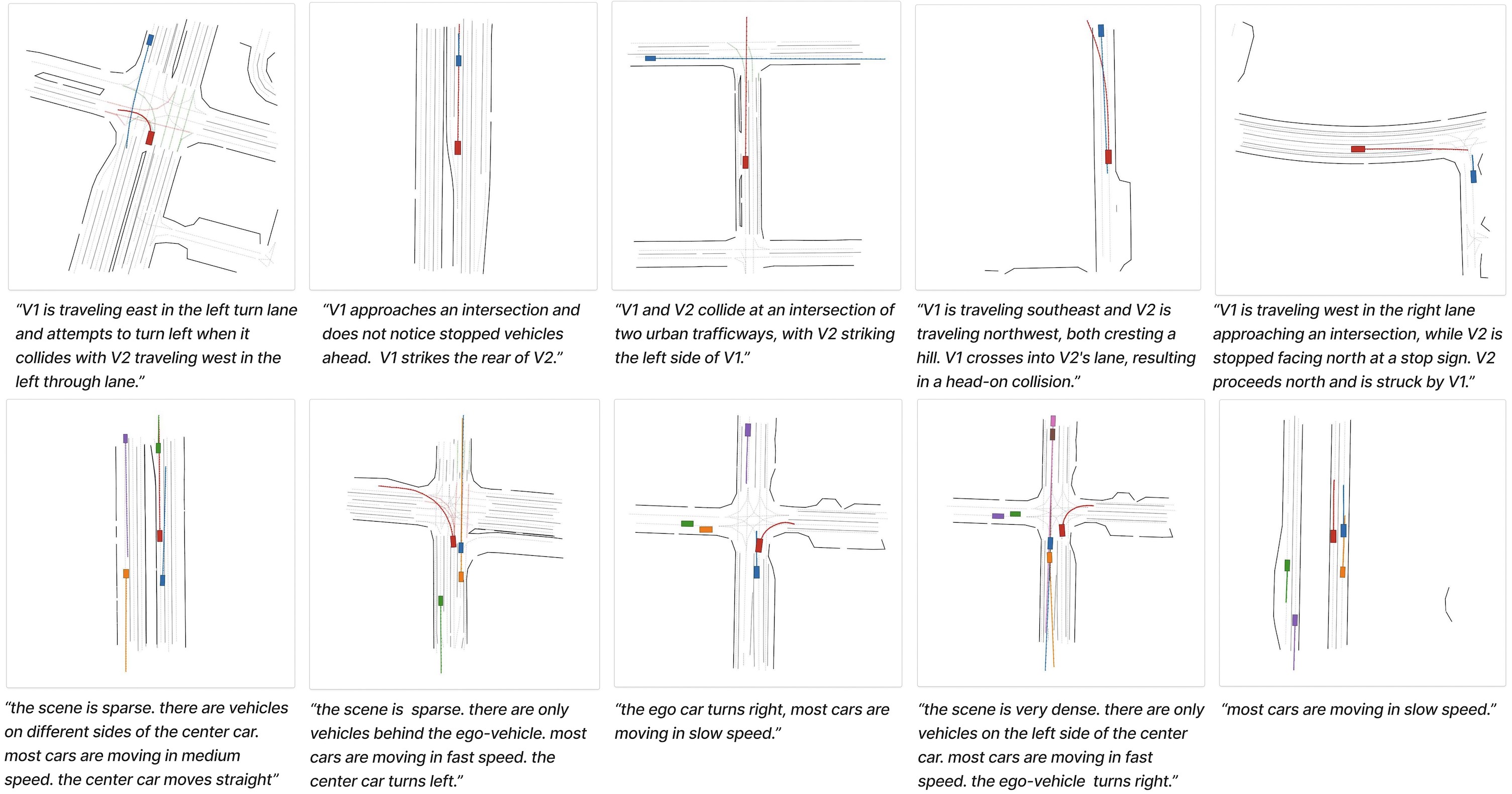
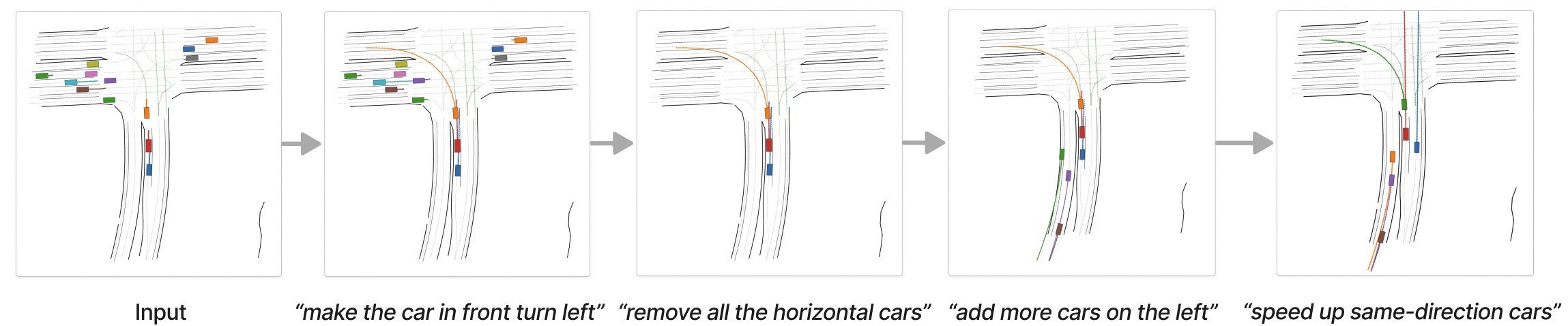
This work presents a language conditioned traffic generation model, LCTGen. Our model takes as input a natural language description of a traffic scenario, and outputs traffic actors' initial states and motions on a compatible map.
Overview
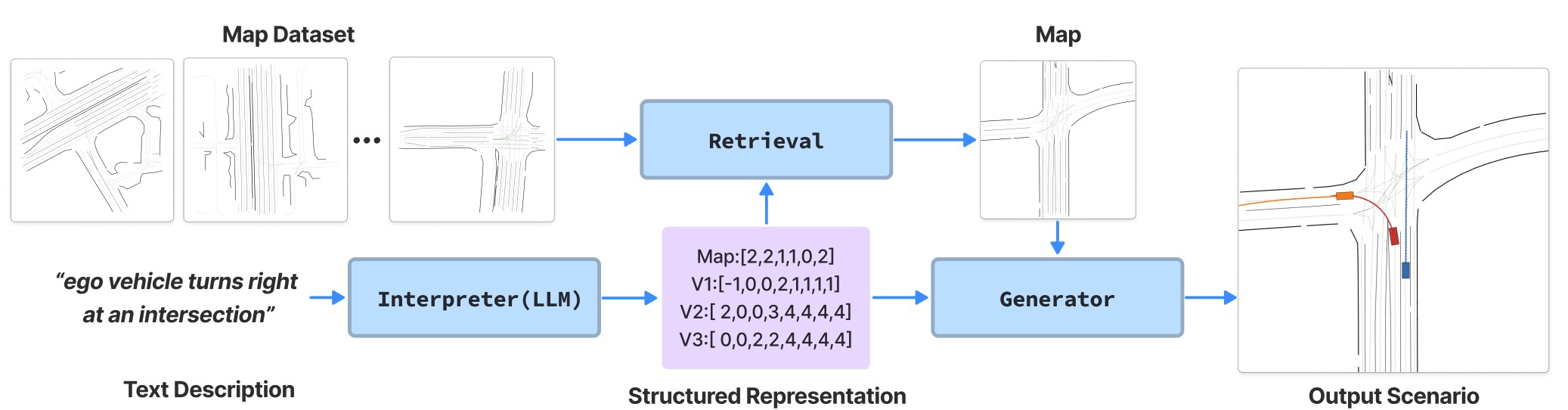
LCTGen has two main modules: Interpreter, and Generator. Given any user-specified natural language query, the LLM-powered Interpreter converts the query into a compact, structured representation. Interpreter also retrieves an appropriate map that matches the described scenario from a real-world map library. Then, the Generator takes the structured representation and map to generate realistic traffic scenarios that accurately follow the user's specifications.

The Interpreter takes a natural language text description as input and produces a structured representation with a LLM (GPT-4). The structured representation describes agent and map-specific information with integer vectors. To obtain the structured representation, we use a large language model (LLM) and formulate the problem into a text-to-text transformation. Specifically, we ask GPT-4 to translate the textual description of a traffic scene into a YAML-like description through in-context learning. An exmaple input-output pair is shown above.
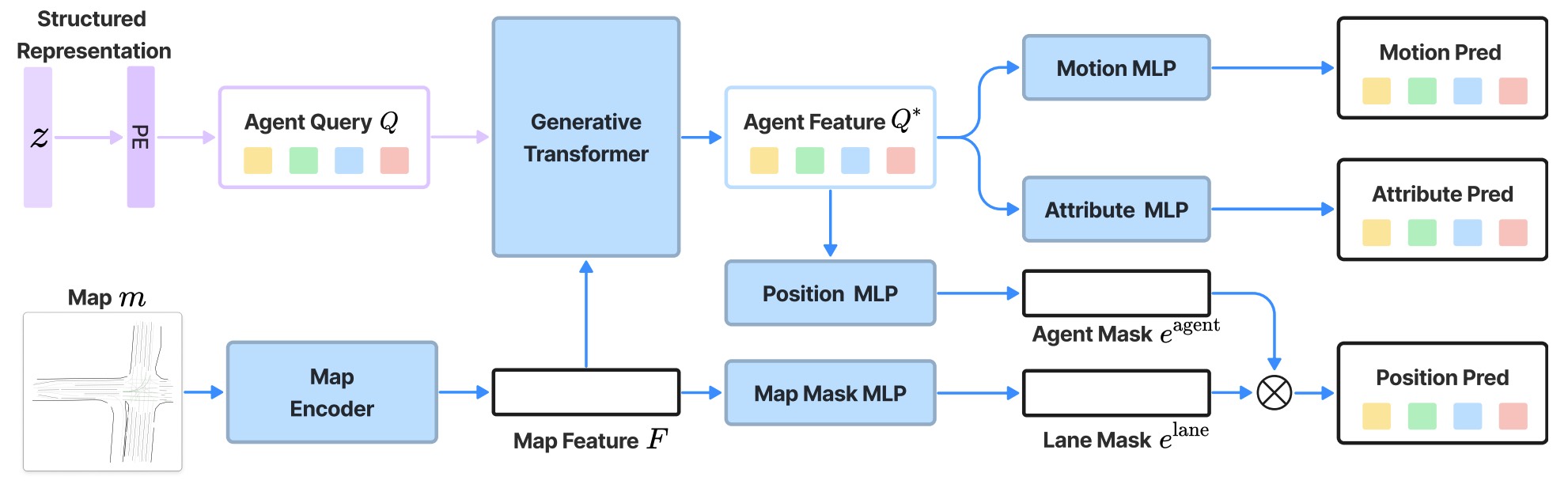
Given a structured representation and map, the Generator produces a traffic scenario (composed of actor initialization and their motion). We design Generator as a query-based transformer model to efficiently capture the interactions between different agents and between agents and the map. It places all the agents in a single forward pass and supports end-to-end training. The Generator has four modules: 1) a map encoder that extracts per-lane map features; 2) an agent query generator that converts structured representation to agent query; 3) a generative transformer that models agent-agent and agent-map interactions; 4) a scene decoder to output the scenario.